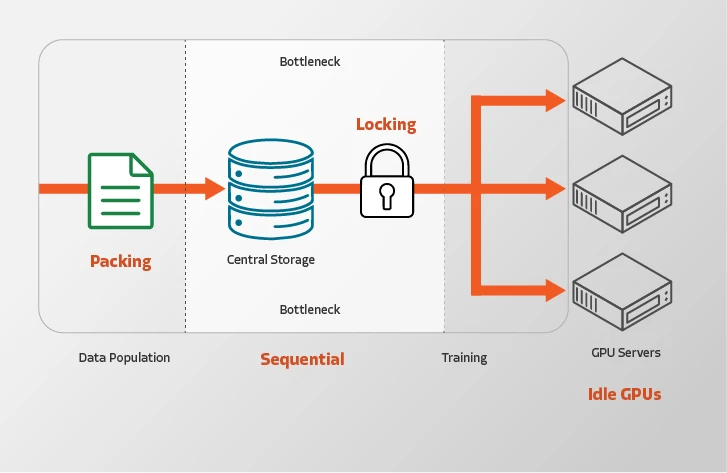
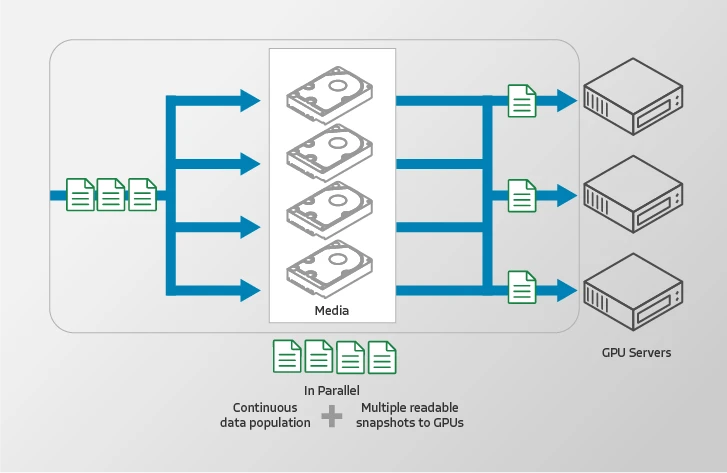
Eliminate the shared storage I/O bottleneck that limits the scale of today’s AI/ML training cycles. Volumez controller-less architecture independently connects each GPU directly to raw NVMe media, eliminating noisy neighbors and the scalability limits of storage controllers, metadata servers, and cluster locks.