
Artificial Intelligence (AI) and Machine Learning (ML) are transforming industries at an accelerated pace, but the success of these technologies hinges on the ability to manage vast amounts of data quickly and efficiently. On-premises and cloud-based shared storage models are often unable to keep up with the demands of AI/ML workloads, leading to bottlenecks, slow training times, and underutilized GPU resources.
That’s where Volumez’s Data Infrastructure as a Service (DIaaS) comes in, which was also announced today. Read the press release and the blog. Our platform is purpose-built to optimize every aspect of the AI/ML data pipeline, from data ingestion and preprocessing to model training and inference. With dynamic scaling, seamless data management, and advanced system balancing, Volumez helps organizations overcome the typical challenges of AI/ML infrastructure.
Most excitingly, we’ve just shattered the MLCommons® MLPerf® Storage 1.0 AI/ML Training performance benchmark, showing the world how our platform revolutionizes infrastructure for AI/ML. Here’s how we did it—and how you can benefit.
How Volumez DIaaS powers AI/ML workloads
Our DIaaS for AI/ML provides solutions for every stage of the AI/ML data pipeline, ensuring that organizations can maximize their infrastructure’s efficiency while minimizing costs. Here’s how we deliver value across the entire pipeline:
- Data Ingestion and Preprocessing helps organizations manage massive datasets with high-speed data handling, ensuring that data is ready for training with minimal delays.
- Optimized AI/ML Training Workloads allow for near 100% GPU utilization and system balancing, so organizations can run more training jobs in parallel and reduce training times.
- Efficient Model Deployment and Inference ensures that models can be deployed at scale with low latency and high availability, whether in real-time or for batch inference.
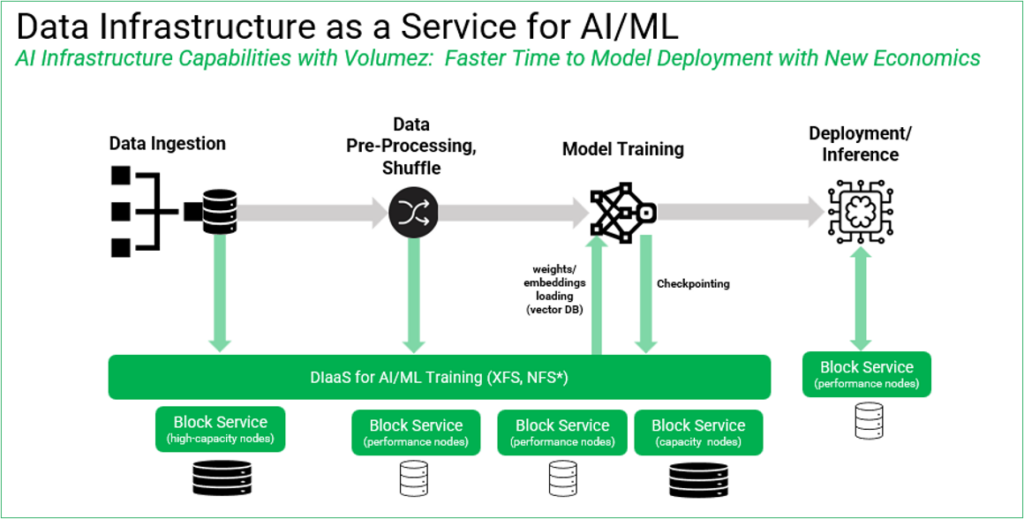
Figure 1: Volumez DIaaS for AI/ML workloads delivers faster time to model deployment with new economics.
Key benefits of Volumez DIaaS for AI/ML
- Scalable infrastructure that adjusts to the needs of AI/ML training, eliminating bottlenecks in data processing and resource utilization.
- Seamless integration of storage and compute resources, enabling faster model training and greater GPU utilization.
- Dynamic system balancing that continuously optimizes performance and cost, allowing businesses to run AI/ML workloads more effectively.
- Simplified data management that provides end-to-end control over the data pipeline, from ingestion to inference.
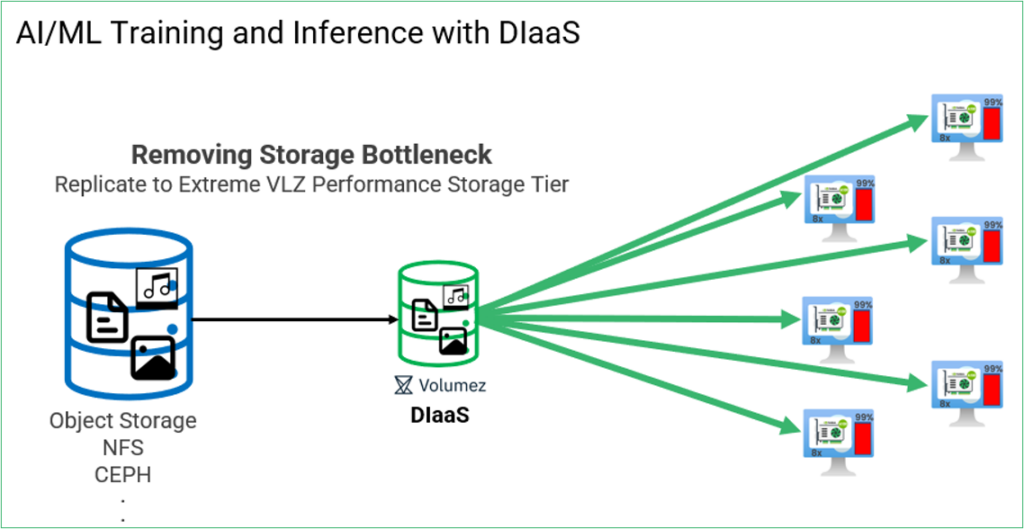
Figure 2: DIaaS for AI/ML eliminates the GPU waste by increasing the GPU utilization to nearly 100%, thus significantly reducing training times and costs.
DIaaS for AI/ML training maximizes the value (utility) of the consumption of one of the cloud’s most precious resources, GPUs. It can be measured similarly to manufacturing processes where GPU Yield = (computational output / total GPU capacity) * 100. DIaaS for AI/ML training maximizes the useful computational output, driving GPU Yield and maximizing your investment on the most expensive infrastructure component in AI/ML.

Figure 3: DIaaS for AI/ML improves AI/ML revenue yield by decreasing training times and increasing job count for the same time on the same GPU.
The results speak for themselves: MLPerf Storage Benchmark
In the recent MLCommons® MLPerf® Storage 1.0 Open Division AI/ML Training Benchmark, Volumez demonstrated the true power of its DIaaS platform. In the MLPerf Storage 1.0 benchmark, focused on the highly storage-intensive 3D-UNet model, Volumez’s DIaaS for AI/ML demonstrated extraordinary linear scaling. It achieved an impressive average throughput of 1.079 TB/sec with 92.21% GPU utilization and 9.9M IOPS1 on AWS. Read the press release.
For the benchmark, we composed 137 application nodes (c5n.18xlarge), each simulating 3 H100s, streaming training data from 128 media nodes (i3en.24xlarge) with 60TB each. No components are added to the 100% Linux data path or deployed as a traditional controller. Instead, the DIaaS platform leverages unique intellectual property to build “awareness” of the capabilities and limitations of cloud IaaS resources. The Volumez “cloud-aware” control plane tailored this infrastructure to the 3D-UNet training workload specified in the benchmark to deliver both unprecedented speed and transformative economics.
Key MLPerf Benchmark Highlights:
- Achieved a peak performance of 1.079 TB/sec throughput
- Delivered 92.21% GPU utilization, ensuring maximum efficiency for training jobs
- Reached an astounding 9.9M IOPS, setting a new standard in data handling for AI/ML workloads
- Proved scalability for large-scale datasets and intensive AI/ML model training
These results prove that Volumez is not only capable of handling the data demands of modern AI/ML workloads but can do so more efficiently than traditional infrastructure solutions. This means organizations can focus on what really matters—accelerating their AI/ML initiatives—without worrying about performance bottlenecks or infrastructure limitations.
To explore the innovative architecture behind Volumez’s DIaaS for AI/ML platform in greater detail, we have released a comprehensive white paper. The document delves into the core architecture highlighting how its tailored data infrastructure is optimized for AI/ML training workloads that delivered the unprecedented results. Read the white paper here.
Get started with Volumez DIaaS for AI/ML
Volumez is redefining what’s possible for AI/ML workloads with its high-performance, scalable DIaaS platform. Whether you’re dealing with medium datasets or scaling up for large, complex AI training models, our platform adapts to your needs, ensuring you get the best performance at the lowest cost.
Contact us today to learn more about how Volumez can transform your AI/ML infrastructure.
1 Results verified by MLCommons Association. Retrieved from https://mlcommons.org/benchmarks/storage/. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.